The Raw Stack: Powering the Post-Frontend Company
I am convinced that LLMs will more and more replace visual frontends and middle layers and go straight to the lowest possible infrastructure and give us voice and text interfaces that will be just enough. Designing frontends is harder to test automatically, also every user needs different views on the same data. We need a base layer that cannot be reduced any more and that gives LLMs all they need to run a company: The raw stack.
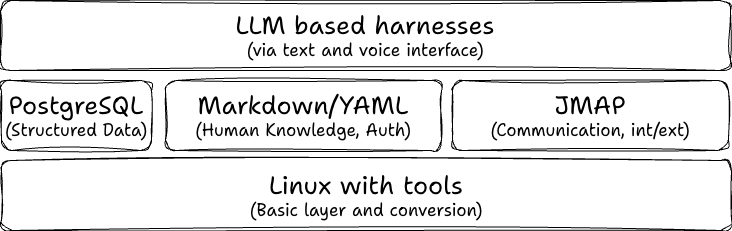
The stack that I think we'll get to is: PostgreSQL for structured data as it can hold both relational and JSON data and has a good built-in text and vector search. It's interface is plain SQL and every LLM can translate to and from human language enough.
The layer for knowledge can either be PostgreSQL as well or Markdown with YAML frontmatter. I bet on Markdown, because it can be easily moved around and changed and via file system has an interface to another foundation layer: Git.
Git is the best way to structure collaboration, no matter whether agents or humans. It will be the invisible layer of "who did what and when?" and will allow to resolve conflicts automatically or surface problems that would have been hidden before.
Some risks with it: Skipping visual frontends will erode mutual understandings of topics. When a company uses a set CRM, the structure enforces one way of work. When you give that up and allow every user to access raw data in any way, this shared language will go away and lead to more transactional costs as you will have to understand whether you really talk about the same thing. Even doing the very thing, e.g. asking the very same question by the very same person, might lead to different answers. Organizations will have to learn to live with a lot more ambiguity.
Also, you get more dependent on the LLM providers. Agents will grow smarter and more specialized, e.g. training an agent on such the above systems and the interface with human language could potentially lead to much smaller, faster models that could run on local machines. This could be faster than even logging into your system, clicking three times to get what you need. But currently, there's practically only a oligopoly of LLM providers that can make you dependent on them easily with walled gardens that integrate deeper into your systems and data than any software before.
So even with a fast local model, you should not always rebuild the wheel but rather have an "app-layer" where everyone can create reusable modules that access. Some tools that can help in this impromptu translation/visualization: Pandoc that can take text and create presentations in HTML, CSS, JS which will replace Powerpoint. Typst can create PDFs for out
JS or Python (later potentially Rust) can be the languages that do the hard work of translating between human language, LLMs and the base layer and create the intermediate apps (Anthropic builds such an infrastructure with Bun and gives you interfaces and locks you into their ecosystem). You don't need much more than the built-in libraries and companies should rather donate to these open source teams than getting in a hold-up with the big LLM vendors.
Authorization is much harder in such a system that excels from openness. First, I think big organizations will have to give up control or collapse into many smaller organizations. For basic auth, the simplest system I can think of is YAML (or TOML) in a folder that is protected by the person that set it up.
Then, there's the communication layer. What is replacing chat apps like Slack and MS Teams and email? It needs to cater for both internal and external communication, so my choice here is JMAP, which is an open Internet standard that would give LLMs standardized APIs for communication.
The full company could be a Linux server that employees access via a terminal that takes their voice and text input and returns the result, be it "unanswered requests that I need to answer", "quote for the lead that visited our website" or "how far on our team goal for this quarter?".
Only brave companies would take that leap, especially if they have history and big, new ones are more likely to reduce to those basics. Smart ones will try to build fast LLMs (on open source foundation models like the smaller Qwens) to get independent . I would hire sysadmins, Linux infrastructure geeks and first-principial thinkers ("What do organizations do and need and how to evaluate LLM results and improve them with examples ourselves?") now to build these foundational layers yourself now and skip getting lost building and tweaking frontend heavy tooling and getting stuck in maintenance hell.